
Guts !!
[패스트 캠퍼스 수강 후기] 올인원 패키지: 직장인을 위한 파이썬 데이터 분석 100% 환급 챌린지 27회차 미션 본문
[패스트 캠퍼스 수강 후기] 올인원 패키지: 직장인을 위한 파이썬 데이터 분석 100% 환급 챌린지 27회차 미션
버블스텝 2020. 11. 14. 22:05[ Python 필수 스킬 - Pandas ]
- 통계값 (min, max, describe // 분산 및 표준편차 )

오늘 포스팅은 통계값 과 분산 및 표준편차에 대해서 공부를 하겠습니다.
[통계값 (min, max, describe // 분산 및 표준편차) ]
df. describe() 데이터프레임에 수치값으로 되어있는 컬럼의 데이터값의 count, 평균값, 표준편차, 최소값 그리고 중앙값에 25% 50% 75% 최대,최소값으로 반환이 된다.

저번에 df.info()라는 명령어를 치게 되면 데이터프레임의 데이터 타입 부터 행과 열의 수 모든 정보를 알 수 있습니다.
count가 13이라는 것은 키값을 보면 13 non-null 즉, 13개 행으로 데이터가 들어가 있다는 것을 알 수 있습니다.

mean() : 평균을 알수 있다. sum(): 데이터의 총합을 알 수 있다.
[ 표준 편차 및 분산 ]
분산과 표준편차는 데이터가 평균으로 부터 얼마나 떨어져 있는지 정도를 나타냅니다.
일반적으로 분산보단 표준편차를 더욱 다룬다. 그리고 분산의 루트가 표준편차이다. 분산은 (데이터-평균)**2 형태임
표준편차를 주로 분산보다 많이 확인하는 이유는 데이터 값이 차후에 몇백만개가 되버리면 이에 제곱근을 해주는 형태인분산의 값들은 그 이상으로 커져버리게 되서 전체적인 시스템에 부하를 주게 된다고 합니다.
그렇기에 그냥 루트를 사용한 표준편차를 사용해서 값을 얻어 낸 다고 볼 수 있습니다.
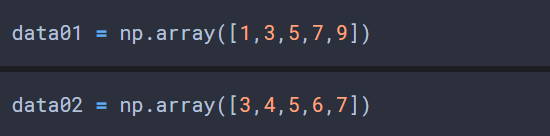
|
data01.mean() # 평균 구하기 > 5.0 data02.mean() > 5.0 data01.var() # 분산 구하기 >8.0 data02.var() >2.0 |
분산 -> (데이터-평균)**2
| a = (data01 - 5) ** 2 a.mean() > 8.0 위의 값은 data01.var() 와 같음. b = (data02 - 5) **2 b.mean() > 2.0 위의 값은 data02.var() 와 같음. |
np.sqrt(data01.var()), np.sqrt(data02.var()) data01.std(), data02.std()  |
df['키'].median() # 중앙값 처리
df['키'].mode() # 최빈값 을 의미 한다. 이는 제일 많이 빈출된 값을 뽑아준다.

오늘의 포스팅은 pandas 강의 중 통계값에 대한 내용이였습니다.
해당 강의 이미지 링크

'FastCampus[직장인] 위한 파이썬(미션)' 카테고리의 다른 글
| [패스트 캠퍼스 수강 후기] 올인원 패키지: 직장인을 위한 파이썬 데이터 분석 100% 환급 챌린지 29회차 미션 (0) | 2020.11.16 |
|---|---|
| [패스트 캠퍼스 수강 후기] 올인원 패키지: 직장인을 위한 파이썬 데이터 분석 100% 환급 챌린지 28회차 미션 (0) | 2020.11.15 |
| [패스트 캠퍼스 수강 후기] 올인원 패키지: 직장인을 위한 파이썬 데이터 분석 100% 환급 챌린지 26회차 미션 (0) | 2020.11.13 |
| [패스트 캠퍼스 수강 후기] 올인원 패키지: 직장인을 위한 파이썬 데이터 분석 100% 환급 챌린지 25회차 미션 (0) | 2020.11.12 |
| [패스트 캠퍼스 수강 후기] 올인원 패키지: 직장인을 위한 파이썬 데이터 분석 100% 환급 챌린지 24회차 미션 (0) | 2020.11.11 |



